最近一个开药店的朋友找我抱怨,有一个同行最近在搞恶性竞争,同类的商品经常标价比他们家少一分钱,应该是从哪来搞来了他们家在外卖平台上的商品数据,从而准对性的进行调价,于是就找到我,问我有没有办法爬取这家同行的数据,想要做一些应对避免流失很对线上的订单,于是就有了这次尝试。
顾虑
一开始我的想法是从Github上找一些开源的方案,简单快速的把数据搞到就行,搜索了一番发现大部分都是四五年前的很久没更新的代码,不能用不说,有的还是搞黑产的做宣传的,于是就放弃了开源方案这一想法。国内的爬虫行业是一个高危职业,处于灰色地带,搞不好就会进去踩缝纫机,再加上外卖平台基本上都是大厂的产品,反扒机制已经做的很全面了,数据爬取的难度比以前也大很多,所以跟朋友话也没说很满,只是答应他先尝试一番再说。
于是就抱着学习同时也遵守相关法律法规和道德规范,不利用抓包技术从事非法活动的想法跟心态开始了一番探索
技术选型
经过一番技术调研,大致了解了各种方案的优缺点
Web\H5 端:
方案:基于Selenium + Chrome的浏览器页面抓取
优点:
- 开发成本较低,有完善的文档和社区支持
- 能够模拟真实用户的浏览行为
- 可以处理动态加载的 JavaScript 内容
- 支持多平台(Windows、Linux、Mac)
- 可以截图和录制浏览过程,便于调试
缺点:
- 运行效率较低,每次请求都需要完整加载浏览器
- 内存占用较大,不适合大规模并发爬取
- 容易被反爬虫系统识别(WebDriver 特征明显)
- 需要安装和维护 Chrome 浏览器及驱动
- 页面结构变化时容易失效,需要经常维护选择器
App 端:
方案:Appium + Python手机端页面数据抓取
优点:
- 更接近真实用户操作,不易被识别为爬虫
- 可以访问移动端专属功能和界面
- 支持多种移动平台(Android/iOS)
- 可以绕过一些针对网页端的反爬措施
- 能够处理复杂的手势操作和动态加载
- 支持录制和回放操作步骤
缺点:
- 环境配置复杂,需要配置
Android SDK、模拟器等 - 运行速度较慢,每次操作都需要等待
UI响应 - 设备资源消耗大,单机并发能力有限
- 当
App版本更新时可能需要更新脚本 - 开发和维护成本相对较高
还有一些更加底层的方案
- 网页端解析拿到
API请求的参数,然后使用目标接口去请求 - 电脑端使用网络请求代理软件直接拦截获取数据
- 手机端底层处理
SSL证书,然后使用抓包工具抓取数据
最后决定使用Appium + Python手机端数据爬取,这个方案跟我的技术栈相对较接近,开始写程序前就是各种软件及开发环境的配置
环境配置
最基础的就是Appium和Appium Inspector的安装,同时使用最通用的UiAutomator2这个Driver。
以下列举所需要的环境配置:
Node环境:Appium和Appium Drivers依赖 Node 环境安装和运行Appium Drivers:需要Appium Drivers在相应的platform上驱动自动化运行,首选推荐UiAutomator2Appium Inspector:用来查看元素的id或者xpath,然后在脚本中查找元素从而进行操作UiAutomator2:安装后使用命令检查必备条件,检查Android SDK、Java JDK等安装及环境变量Android设备:一个Android模拟器或者真实设备
UiAutomator2 是 Appium Drivers 的一种,是官方比较推荐的,安装完成后可以使用
appium driver install uiautomator2命令来检查。
目前一些的介绍Appium文章比较老旧,还是官方文档最靠谱,不熟悉的概念可以通过AI去了解
初步方案
Appium是手机跨端进行自动化测试的一种方案,可以使用很多语言与之交互,包括JS、Python、Java、Ruby和.NET,我选了我相对比较熟悉的Python进行开发。
整个开发过程就是使用Appium提供的API来模拟用户操作,流程如下:
打开目标 APP -> 等待主页显示并关闭一些弹窗 -> 在主页检查目标地址(不符合则进行地址选取操作) -> 到搜索页搜索关键字 -> 寻找目标商家并进入商家详情 -> 开始一系列收集数据的操作。
在开发层面也做了一些处理:
- 封装基本的 Appium 操作,像
find_element、click_element、input_text、get_element_text和swipe等操作 - 创建
meichant、category和durgs三个表,使用Sqlite保存对应数据 - 支持流程中断后从中断出继续爬取,且一天之内只爬取一次
drugs数据 - 数据爬取完后直接生成
Excel并作为邮件附件发送出去
AI 助力
我目前使用的是Trae这个IDE来进行开发,虽然Chat模式访问比其他AI编辑器慢,但好在免费且能使用Claude-3.5-Sonnet这个AI模型,相比于其他模型Claude的模型的回答比较准确。
以下是我用AI帮我做的事:
- 帮我了解
Appium的使用方式,方案细节等 - 生成创建数据库表的 SQL,生成对应的
SQL操作和单元测试 - 封装基本常用的
Appium页面元素操作,并优化swipe等操作细节 - 发送流程细节来生成基础代码,虽然代码意图上并不完全符合我的意图
- 导出
Excel和发送Email操作,封装为工具类
AI 基本伴随我整个开发过程,确确实实的提高了开发效率,按照工作日来算的话,总体花费大概五个工作日左右,如果没有AI的话可能多2-3个工作日。
最终方案
因为外卖 App 涉及到多个,我这里把对应的 xpath 放到config.json里,每个端放置对应 xpath 集合,在程序中只要做一些兼容处理即可。
整个处理流程如下: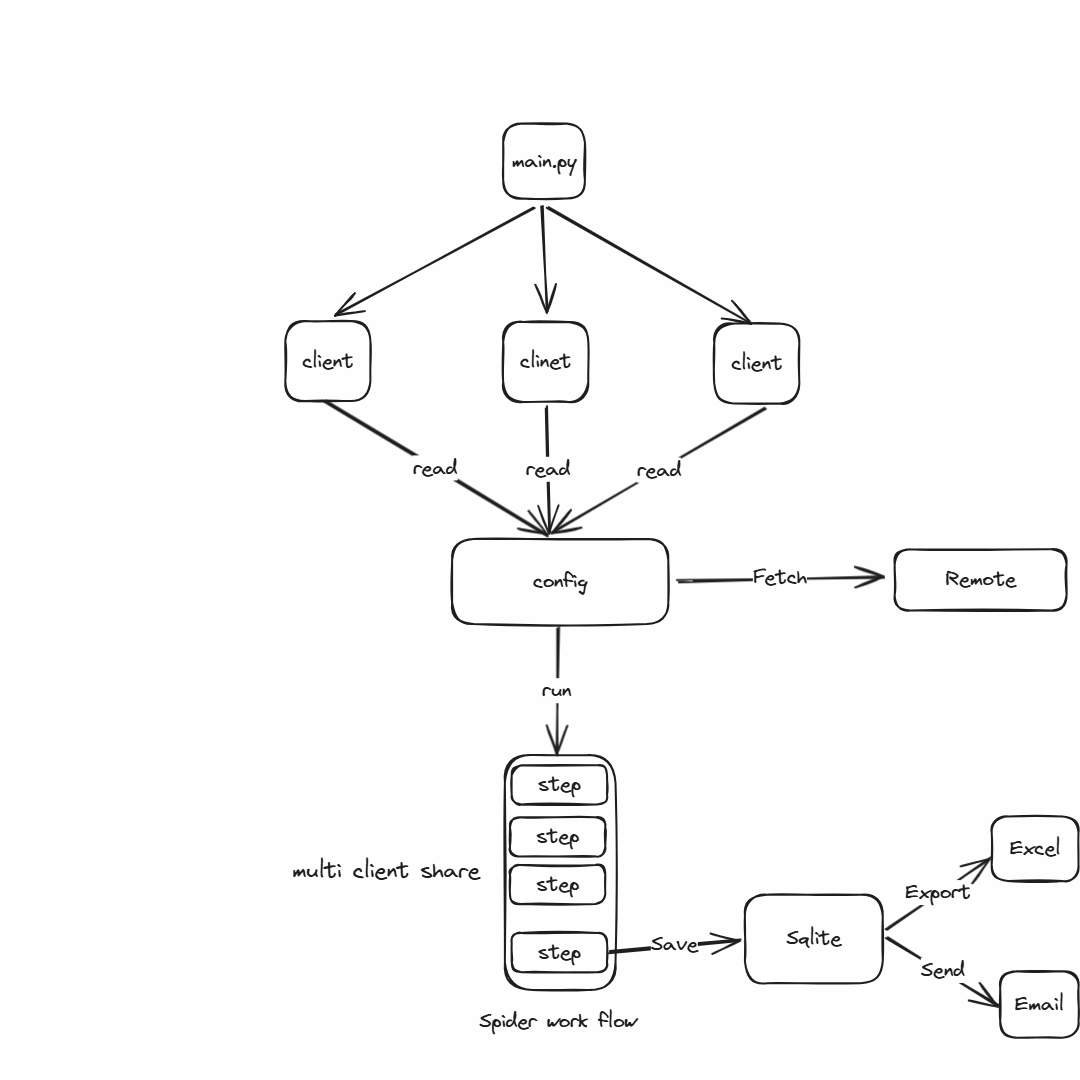
后续计划
- 提供爬虫的多样性,实现 Web\H5 页面的数据爬取
- 使用
Next.js开发一个数据展示页面,提供简单的查询和排序操作 - 使用
PyQt5等开发一个可视化操作界面,让非开发人员也能操作使用
总结
整体上来说Appium + Python这个方案可以说缺点都遇到了,环境配置多且繁琐,步骤复杂且耗时比较久,不能进行大批量且频繁的操作,为此我的两个账号还被官方重点照顾了,动不动就弹出验证弹框验证,不过好在我只需要一份参考数据。